Assessing the Significance of an Alignment
This example shows a method that can be used to investigate the significance of sequence alignments. The number of identities or positives in an alignment is not a clear indicator of a significant alignment. A permutation of a sequence from an alignment will have similar percentages of positives and identities when aligned against the original sequence. The score from an alignment is a better indicator of the significance of an alignment. This example uses the same Tay-Sachs disease related genes and proteins analyzed in Aligning Pairs of Sequences.
Accessing NCBI Data from the MATLAB® Workspace
In this example, you will work directly with protein data so use getgenpept instead of getgenbank to download the data from the NCBI site. First read the human protein information into MATLAB®.
humanProtein = getgenpept('NP_000511');
Results from a BLASTX search performed with this sequence showed that a Drosophila protein, GenPept accession number AAM29423, has some similarity to the human HEXA sequence. Use getgenpept to download this sequence.
flyProtein = getgenpept('AAM29423');
For your convenience, previously downloaded sequences are included in a MAT-file. Note that data in public repositories is frequently curated and updated; therefore the results of this example might be slightly different when you use up-to-date datasets.
load('flyandhumanproteins.mat','humanProtein','flyProtein') seqdisp(humanProtein) seqdisp(flyProtein)
ans =
10×70 char array
'>gi|189181666|gb|NP_000511.2| beta-hexosaminidase subunit alpha pre...'
' 1 MTSSRLWFSL LLAAAFAGRA TALWPWPQNF QTSDQRYVLY PNNFQFQYDV SSAAQPGCSV'
' 61 LDEAFQRYRD LLFGSGSWPR PYLTGKRHTL EKNVLVVSVV TPGCNQLPTL ESVENYTLTI'
'121 NDDQCLLLSE TVWGALRGLE TFSQLVWKSA EGTFFINKTE IEDFPRFPHR GLLLDTSRHY'
'181 LPLSSILDTL DVMAYNKLNV FHWHLVDDPS FPYESFTFPE LMRKGSYNPV THIYTAQDVK'
'241 EVIEYARLRG IRVLAEFDTP GHTLSWGPGI PGLLTPCYSG SEPSGTFGPV NPSLNNTYEF'
'301 MSTFFLEVSS VFPDFYLHLG GDEVDFTCWK SNPEIQDFMR KKGFGEDFKQ LESFYIQTLL'
'361 DIVSSYGKGY VVWQEVFDNK VKIQPDTIIQ VWREDIPVNY MKELELVTKA GFRALLSAPW'
'421 YLNRISYGPD WKDFYIVEPL AFEGTPEQKA LVIGGEACMW GEYVDNTNLV PRLWPRAGAV'
'481 AERLWSNKLT SDLTFAYERL SHFRCELLRR GVQAQPLNVG FCEQEFEQT '
ans =
12×70 char array
'>gi|21064387|gb|AAM29423.1| RE17456p [Drosophila melanogaster]. '
' 1 MSLAVSLRRA LLVLLTGAIF ILTVLYWNQG VTKAQAYNEA LERPHSHHDA SGFPIPVEKS'
' 61 WTYKCENDRC MRVGHHGKSA KRVSFISCSM TCGDVNIWPH PTQKFLLSSQ THSFSVEDVQ'
'121 LHVDTAHREV RKQLQLAFDW FLKDLRLIQR LDYGGSSSEP TVSESSSKSR HHADLEPAAT'
'181 LFGATFGVKK AGDLTSVQVK ISVLKSGDLN FSLDNDETYQ LSTQTEGHRL QVEIIANSYF'
'241 GARHGLSTLQ QLIWFDDEDH LLHTYANSKV KDAPKFRYRG LMLDTSRHFF SVESIKRTIV'
'301 GMGLAKMNRF HWHLTDAQSF PYISRYYPEL AVHGAYSESE TYSEQDVREV AEFAKIYGVQ'
'361 VIPEIDAPAH AGNGWDWGPK RGMGELAMCI NQQPWSFYCG EPPCGQLNPK NNYTYLILQR'
'421 IYEELLQHTG PTDFFHLGGD EVNLDCWAQY FNDTDLRGLW CDFMLQAMAR LKLANNGVAP'
'481 KHVAVWSSAL TNTKRLPNSQ FTVQVWGGST WQENYDLLDN GYNVIFSHVD AWYLDCGFGS'
'541 WRATGDAACA QYRTWQNVYK HRPWERMRLD KKRKKQVLGG EVCMWTEQVD ENQLDNRLWP'
'601 RTAALAERLW TDPSDDHDMD IVPPDVFRRI SLFRNRLVEL GIRAEALFPK YCAQNPGECI'
A First Comparison and Global Alignment
The first thing to do is to use seqdotplot to see if there are any areas that are clearly aligned. This doesn't show any obvious alignments, but there are some areas of interest.
seqdotplot(humanProtein,flyProtein,3,2) title('Dot Plot of Two HexA-like Proteins'); ylabel('Human Protein');xlabel('Drosophila Protein');
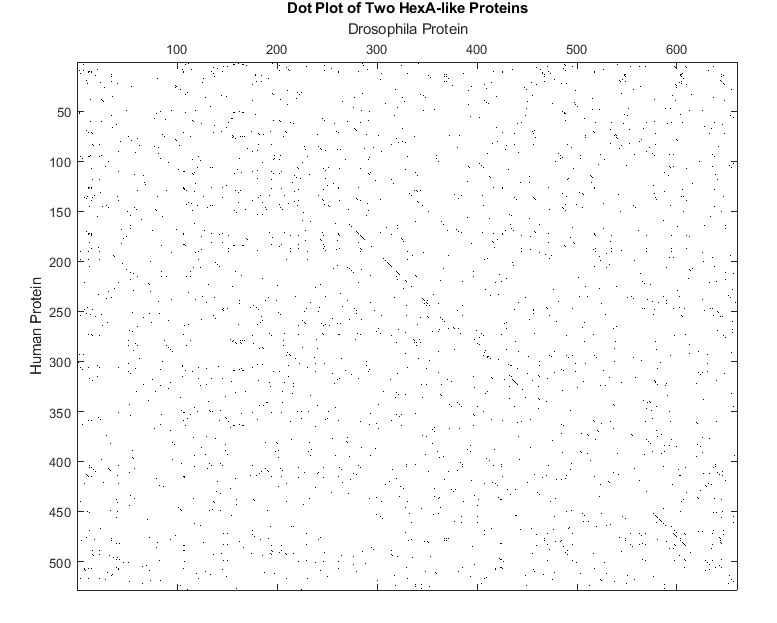
Notice that there are a few diagonal stretches in the dot plot. This is not particularly good evidence of a significant global alignment, but you can try a global alignment using the function nwalign. The BLOSUM50 scoring matrix is used by default.
[sc50,globAlig50] = nwalign(humanProtein,flyProtein)
fprintf('Score = %g \n',sc50)
sc50 =
49.6667
globAlig50 =
3×670 char array
'MT-S-S--R----LW----F--SLL-----LA-A-AF--A-GR------ATAL-WP----W--P-QN---FQT-----SDQR--Y---------V-LYPN---NF----Q---FQY-DVS---SAAQPGC-SVLDEAFQRY-RD--L---L-F-GSGSWPR-PYLTGK-R-HT-LE-KNVLV-VSV-V-TPG--CN-Q-----LPT--LE-SVEN---YTL-TIND-D--QCLLLSETVWGALRGLETFSQLVWKSAEGTFF--INKTEIEDFPRFPHRGLLLDTSRHYLPLSSILDTLDVMAYNKLNVFHWHLVDDPSFPYESFTFPELMRKGSYNPVTHIYTAQDVKEVIEYARLRGIRVLAEFDTPGH--T-LSWGP--GIPGLLTPCYSGSEP-S---G--TFGPVNPSLNNTYEFMSTFFLE-VSSVFP-DFYLHLGGDEVDFTCWKSNPEIQDFMRKKGFGEDFKQLESFYIQTLLDIVSSYGKGYVVWQEVFDNKVKIQPDT-I-IQVWREDI-PVNY--MKE-LELV-TKAGFRAL-LS-APWY-LNRISYGP--DWKDFYIVEPLA-FEGTPEQKALVIGGEACMWGEYVDNTNLVPRLWPRAGAVAERLWSNKLTS-DLTF----AYERLSHFRCELLRRGVQAQPLNVGFCEQE-FEQT'
'|: : | | | | ::| :: | |: | | |::: | | :| ::: | :| : | ::|: :| | |: ||: ::|: : |: ||: : :| | | : ||:| | ::| | |: || :| :: | | : | | : |: |::| | | | :: | ::::: :|| :|| |::||:| : | :: :::::| |:| :|||:||||||:: : || |: |: |:| |||||:| |||| | :||| :|:|: :: |: |||:|| |:|:: |::|: |:|:|:| : :||| |: | |: | : ::| | | | :||: | || ::: :: | :: : | ||: |||||||:: || : : | :| |: || :|:: : : | : | :||: :: | :: |:: : :||| : || : : ::: ::: | : : | : : : |:: | :| :: ::| |:|||:||| | ||:::| |||||::|:|||||:: : |: : :::|:| || :|:: |::|: | :| |: | '
'MSLAVSLRRALLVLLTGAIFILTVLYWNQGVTKAQAYNEALERPHSHHDASGFPIPVEKSWTYKCENDRCMRVGHHGKSAKRVSFISCSMTCGDVNIWPHPTQKFLLSSQTHSFSVEDVQLHVDTAHREVRKQLQLAFDWFLKDLRLIQRLDYGGSSSEPTVSESSSKSRHHADLEPAATLFGATFGVKKAGDLTSVQVKISVLKSGDLNFSLDNDETYQLSTQTEGHRLQVEIIANSYFGARHGLSTLQQLIWFDDEDHLLHTYANSKVKDAPKFRYRGLMLDTSRHFFSVESIKRTIVGMGLAKMNRFHWHLTDAQSFPYISRYYPELAVHGAYSE-SETYSEQDVREVAEFAKIYGVQVIPEIDAPAHAGNGWDWGPKRGM-GELAMCIN-QQPWSFYCGEPPCGQLNPKNNYTYLILQRIYEELLQHTGPTDFF-HLGGDEVNLDCWAQYFNDTD-LR--GLWCDF-MLQA-MARLKLANNGVAPKHVAVWSSALTNTKRL-PNSQFTVQVWGGSTWQENYDLLDNGYNVIFSHVDAWYLDCGFGSWRATGDAACAQYRTWQNVYKHRPWERMRLDKKRKKQVLGGEVCMWTEQVDENQLDNRLWPRTAALAERLWTDPSDDHDMDIVPPDVFRRISLFRNRLVELGIRAEALFPKYCAQNPGECI'
Score = 49.6667
The sequence similarity is fairly low, so BLOSUM30 might be a more appropriate scoring matrix.
[sc30,globAlig30] = nwalign(humanProtein,flyProtein,'scoringmatrix','blosum30') fprintf('Score = %g \n',sc30)
sc30 =
82
globAlig30 =
3×670 char array
'MT-S-S--R-----L-W--F--S-LL----L--AAAF--A-GR------ATAL-WP----W--P-QN-F--QT-----SDQR--Y---------V-LY--PN-NF----Q---F-----QY--DVS-SAAQPGCS-VLDEAFQ--RY-RDLLF-GSGSWP-RPYLTGK-R-HT-LEK-NVLV-VSV-VTP-G-CN--QLP-T-LESVE-NYTLTINDD--QC-L-L----L-SETV---W-GALRGLETFSQLVWKSAEGTFF-I-NKTEIEDFPRFPHRGLLLDTSRHYLPLSSILDTLDVMAYNKLNVFHWHLVDDPSFPYESFTFPELMRKGSYNPVTHIYTAQDVKEVIEYARLRGIRVLAEFDTPGH--T-LSWGPGIP-GLLTPCYSGSEP-S---G--TFGPVNPSLNNTYEFMSTFFLE-VSSVFP-DFYLHLGGDEVDFTCWKSNPEIQDFMRKKGFGEDFKQLESFYIQTLLDIVSSYGKGYVVWQEVFDNKVKIQPDT--IIQVWREDI-PVNY--MKE-LELV-T--KAGFRALLSAPWY-L-NRI-SYGPDWKDFYIVEPLAFEGT-PEQKALVIGGEACMWGEYVDNTNLVPRLWPRAGAVAERLWSNK-LTSDL-TF---AYERLSHFRCELLRRGVQAQPLNVGFCEQ-EFEQT'
'|: : | | | : | : |: : |:|: | | |::: | | : :| :: |::| : | :: |: :| | | |: |:: :::: : ::| :: |: : | : ||:| | ::| | |: ||: ::|: ::: | : | :: |:: : |:| : |::| ||: |: : : | |:: : || ||:|: ||:| ::| :: : ::::::| |:| :|||:||||||:: ::|| |: |:::|:| |||||:|::|||| | :|||: |:|:: :::|::|||:||:|:|:::|::|: |:|:|:| : :||| | |: | : :| | | : |::||: | || :: :: | : : | ||: |||||||:: || : : : | : :|:::||: |:: ::: |:: : | ::|| ::: | :| |:: ::||| :: : || :: : :: : :|:: :: : |: : : : : |:::| | : : :::|: |:|||:||| | || : | |||||::|:|||||::: |: :: :: |:| || |: |::|: | :|:| : | :'
'MSLAVSLRRALLVLLTGAIFILTVLYWNQGVTKAQAYNEALERPHSHHDASGFPIPVEKSWTYKCENDRCMRVGHHGKSAKRVSFISCSMTCGDVNIWPHPTQKFLLSSQTHSFSVEDVQLHVDTAHREVRKQLQLAFDWFLKDLRLIQRLDYGGSSSEPTVSESSSKSRHHADLEPAATLFGATFGVKKAGDLTSVQVKISVLKSGDLNFSLD-NDETYQLSTQTEGHRLQVEIIANSYFGARHGLSTLQQLIWFDDEDHLLHTYANSKVKDAPKFRYRGLMLDTSRHFFSVESIKRTIVGMGLAKMNRFHWHLTDAQSFPYISRYYPELAVHGAYSE-SETYSEQDVREVAEFAKIYGVQVIPEIDAPAHAGNGWDWGPKRGMGELAMC-INQQPWSFYCGEPPCGQLNPKNNYTYLILQRIYEELLQHTGPTDFF-HLGGDEVNLDCW-A-QYFND-TDLRGLWCDFM-LQA-MARLKLANNGVAPKHVAVWSSALTN-TKRLPNSQFTVQVWGGSTWQENYDLLDNGYNVIFSHVDAWYLDCGFGSWRATGDAACAQYRTWQNVYKHRPWERMRLDKKRKKQVLGGEVCMWTEQVDENQLDNRLWPRTAALAERLWTDPSDDHDMDIVPPDVFRRISLFRNRLVELGIRAEALFPKYCAQNPGECI'
Score = 82
This gives an alignment that has some areas of fairly strong similarity, but is this alignment statistically significant? One way to investigate whether this score is significant is to use Monte Carlo techniques. Given that the fly sequence was found using a BLAST search, there is some evidence that there is similarity between the two sequences. It is reasonable to expect the score for this alignment to be higher than the scores obtained from aligning random sequences of amino acids to the protein.
Assessing the Significance of the Score
To assess if the score is significant the first step is to make some random sequences that are similar to that of the fly protein. One way to do this is to take random permutations of the fly sequence. This can be done with the randperm function. Then calculate the global alignment of these random sequences against the human protein and look at the statistical significance of the scores.
Initialize the state of the default random number generators to ensure that the figures and results generated match the ones in the HTML version of this example.
rng(0,'twister') n = 50; globalscores = zeros(n,1); flyLen = length(flyProtein.Sequence); for i = 1:n perm = randperm(flyLen); permutedSequence = flyProtein.Sequence(perm); globalscores(i) = nwalign(humanProtein,permutedSequence,'scoringmatrix','blosum30'); end
Now plot the scores as a bar chart. Note that because you are using randomly generated sequences.
figure buckets = ceil(n/5); hist(globalscores,buckets) hold on; stem(sc30,1,'k') title('Determining Alignment Significance using Monte Carlo Techniques'); xlabel('Score'); ylabel('Number of Sequences');
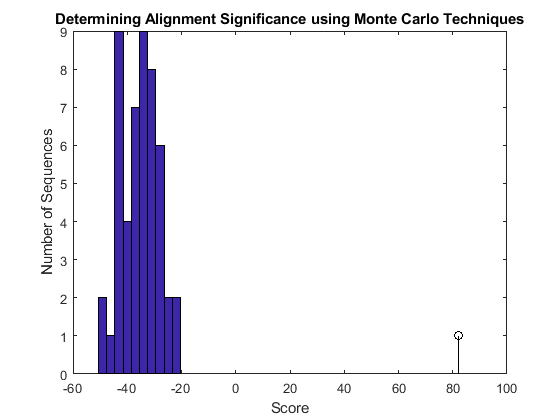
The scores of the alignments to the random sequences can be approximated by the type 1 extreme value distribution. Use the evfit function from the Statistics and Machine Learning Toolbox™ to estimate the parameters of this distribution.
parmhat = evfit(globalscores)
parmhat = -31.7597 6.6440
Overlay a plot of the probability density function of the estimated distribution.
x = min(globalscores):max([globalscores;sc30]); y = evpdf(x,parmhat(1),parmhat(2)); [v, c] = hist(globalscores,buckets); binWidth = c(2) - c(1); scaleFactor = n*binWidth; plot(x,scaleFactor*y,'r'); hold off;
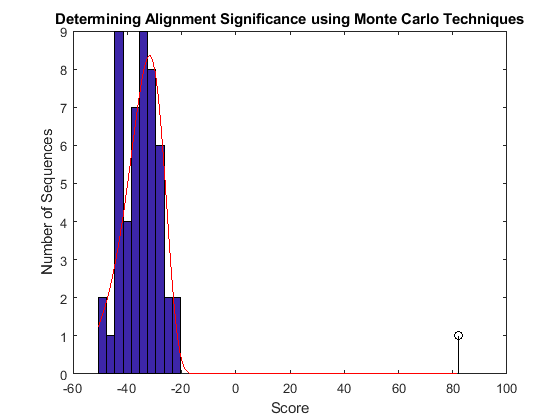
From this plot you can see that the global alignment (globAlig30) is clearly statistically significant.
An Example Where the Score is Not Statistically Significant
In FLYBASE web site you can search for all Drosophila beta-N-acetylhexosaminidase genes. The gene that you have been looking at so far is referenced as CG8824. Now you want to take a look at another similar gene, for instance Hexo1.
flyHexo1 = getgenpept('AAL28566');
The fly Hexo1 aminoacid sequence is also provided in the MAT-file flyandhumanproteins.mat.
load('flyandhumanproteins.mat','flyHexo1') seqdisp(humanProtein)
ans =
10×70 char array
'>gi|189181666|gb|NP_000511.2| beta-hexosaminidase subunit alpha pre...'
' 1 MTSSRLWFSL LLAAAFAGRA TALWPWPQNF QTSDQRYVLY PNNFQFQYDV SSAAQPGCSV'
' 61 LDEAFQRYRD LLFGSGSWPR PYLTGKRHTL EKNVLVVSVV TPGCNQLPTL ESVENYTLTI'
'121 NDDQCLLLSE TVWGALRGLE TFSQLVWKSA EGTFFINKTE IEDFPRFPHR GLLLDTSRHY'
'181 LPLSSILDTL DVMAYNKLNV FHWHLVDDPS FPYESFTFPE LMRKGSYNPV THIYTAQDVK'
'241 EVIEYARLRG IRVLAEFDTP GHTLSWGPGI PGLLTPCYSG SEPSGTFGPV NPSLNNTYEF'
'301 MSTFFLEVSS VFPDFYLHLG GDEVDFTCWK SNPEIQDFMR KKGFGEDFKQ LESFYIQTLL'
'361 DIVSSYGKGY VVWQEVFDNK VKIQPDTIIQ VWREDIPVNY MKELELVTKA GFRALLSAPW'
'421 YLNRISYGPD WKDFYIVEPL AFEGTPEQKA LVIGGEACMW GEYVDNTNLV PRLWPRAGAV'
'481 AERLWSNKLT SDLTFAYERL SHFRCELLRR GVQAQPLNVG FCEQEFEQT '
Repeat the process of generating a global alignment and then using random permutations of the amino acids to estimate the significance of the global alignment.
[Hexo1score,Hexo1Alignment] = nwalign(humanProtein,flyHexo1,'scoringmatrix','blosum30') fprintf('Score = %g \n',Hexo1score) Hexo1globalscores = zeros(n,1); flyLen = length(flyHexo1.Sequence); for i = 1:n perm = randperm(flyLen); permutedSequence = flyHexo1.Sequence(perm); Hexo1globalscores(i) = nwalign(humanProtein,permutedSequence,'scoringmatrix','blosum30'); end
Hexo1score =
-72.2000
Hexo1Alignment =
3×534 char array
'MTSSRL-WFSLLLAAAFA-GRATALWPWPQNFQTSDQRYVLYPNNFQFQYDVSSAAQPGCSVLDEAFQRYRDLLFGSGSWPRPYLTGKRHTLEKNVLVVSVVTPGC-NQLPTLESVENYTLTINDDQCLLLSETVWGALRGLETFSQLVWKSAEGTFFINKTEIEDFPRFPHRGLLLDTSRHYLPLSSILDTLDVMAYNKLNVFHWHLVDDPSFPYESFTFPELMRKGSYNPVTHIYTAQDVKEVIEYARLRGIRVLAEFDTPGHTLSWGPGIPGLLTPCYSGSEPSGTFGPVNPSLNNTYEFMSTFFLEVSSVFPDFYLHLGGD-EV-DFTCWKSNPEIQDFMRKKGFGEDFKQLESFYIQTLLDIVSSYGKGYVVWQEVFDNKVKIQPDTIIQVWREDIPVNYMKELELVTKAGFRALLSAPWYLNRISYGPDWKDFYIVEPLAFEGTPEQKALVIGGEACMWGEYVDNTNLVPRLWPRAGAVAERLWSNKLTSDLTFAYERLSHFRCELLRRGVQAQPLNVGFCEQEFEQT'
'|: :| | :::: : ::: :| ::: : :|| | | : : : ||::::: | | :: |:: | : : | :: | :| || : | :| |: | :| : : : : :| |::|| ::: :::: : :: || | :: ::|: | |:| | : : :| :: : : : : :| : ::::: :|: | || ::: : |::: :: |::|: : : | :| : | | |: | | :|:|:: : :| | |:|::::::| :: : : ||: : ::|| :||: | | : | | | | : :| : | : |:| |: :: :|: ::| | :| : : |: ::| | :: : :| :: | | | | :: | |: :| : :: |: || :| : | :: : : |: | : :| : :: | | |: || |:| :: : :: :'
'MALVKLNTFHWHITDSHSFPLEVKKRPELHKLGAYSQRQV-Y--T-R-R-DVAEVVEYG-RV--RGI-RVMP-EF-D-A-PAHVGEGWQH---KN-M-----T-ACFNAQP-WKS---F-C-V-EPPCGQLDPTV-NEM--YDVL-EDIY----GTMF-DQF-NPDI--F-HMG--GD---E-VS-TSCWNS-S--Q--P--IQQW-M-KKQGWGLETADF---MRLWGHFQ-TEAL-GR-VDKVANGTHT-PI-IL--W-TSG--LTEEPFIDEYLNPERYIIQ-IWTTG-VDPKVKKILE-RG-YKIIVSN-YDALYLDCGGAGWVTDGNNWCS-PYI-GW-QKV-Y--D-NSLKS--IAGDYEH-HVLGAEGAIWSEQID-EHTL--DN--RFW----P--RA-S-AL-AE---R--L---W-SNPAE-G--WR--Q-AES-RLL-LHRQR-LVDNG---L-G--AE-A-MQPQ-W-CL-Q-NE-H-ECPI--D---A--------CS---RGSGRLGLIVLLLLTTLS-A'
Score = -72.2
Plot the scores, calculate the parameters of the distribution and overlay the PDF on the bar chart.
figure buckets = ceil(n/5); hist(Hexo1globalscores,buckets) title('Determining Alignment Significance using Monte Carlo Techniques'); xlabel('Score'); ylabel('Number of Sequences'); hold on; stem(Hexo1score,1,'c') parmhat = evfit(Hexo1globalscores) x = min(Hexo1globalscores):max([Hexo1globalscores;Hexo1score]); y = evpdf(x,parmhat(1),parmhat(2)); [v, c] = hist(Hexo1globalscores,buckets); binWidth = c(2) - c(1); scaleFactor = n*binWidth; plot(x,scaleFactor*y,'r'); hold off;
parmhat = -70.6926 7.0619
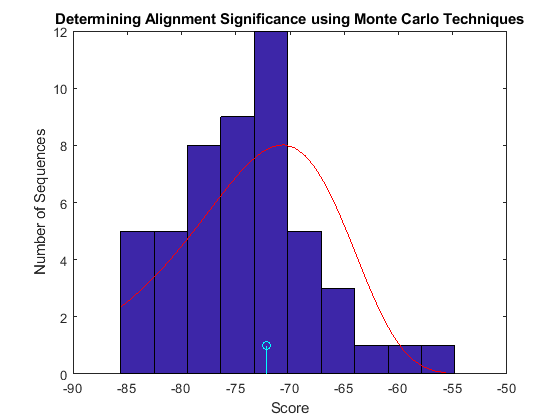
In this case it appears that the alignment is not statistically significant. Higher scoring alignments can easily be generated from a random permutation of the amino acids in the sequence. You can calculate an approximate p-value from the estimated extreme value CDF: However, far more than 50 random permutations are needed to get a reliable estimate of the extreme value pdf parameters from which to calculate a reasonably accurate p-value.
p = 1 - evcdf(Hexo1score,parmhat(1),parmhat(2))
p =
0.4458
One thing to notice is that the lengths of the two sequences are very different. The human HEXA1 is 529 residues long and the fly Hexo1 protein is only 383 residues in length. When you try to align these two sequences globally this difference in length means that a large number of gaps will have to be introduced into the sequence. This means that the significance of the scores will be heavily dependent on the GAPOPEN and EXTENDGP parameters. (See the help for nwalign for more details.) Instead of using global alignment, in this case a better approach might be to look at the local alignment between the two sequences.
Using Local Alignment and Randseq
You will now repeat the process of estimating the significance of an alignment this time using local alignment and a slightly different method of generating the random sequences. Instead of simply permuting the letters in the sequence, an alternative is to draw a sequence from a multinomial distribution which is estimated from the fly protein sequence. You can do this using the aacount and randseq functions; the first estimates the amino acid frequencies of the query sequence and the later randomly creates new sequences based on this distribution.
[lscore,locAlig] = swalign(humanProtein,flyHexo1,'scoringmatrix','blosum30') fprintf('Score = %g \n',lscore) localscores = zeros(n,1); aas = aacount(flyHexo1); for i = 1:n randProtein = randseq(flyLen,'FROMSTRUCTURE',aas); localscores(i) = swalign(humanProtein,randProtein,'scoringmatrix','blosum30'); end
lscore =
152
locAlig =
3×361 char array
'MAYNKLNVFHWHLVDDPSFPYESFTFPELMRKGSYNPVTHIYTAQDVKEVIEYARLRGIRVLAEFDTPGHT-LSWG-PGIPGLL-TPCYSGSEPSGTFGPVNPSLNNTYEFMSTFFLEVSSVF-PDFYLHLGGDEVDFTCWKSNPEIQDFMRKKGFG-E--DFKQLES-FYIQTL--LD-IVSSYGKGYVVWQE-VFDNK-V-K-IQPD-TIIQVWREDI-P-VNYMKELEL-VTKAGFRALLSAPWYLNRISYGPDWKDFYI-VEP-L--AFEG-TPEQKALVIGGEACMWGEYVDNTNLVPRLWPRAGAVAERLWSNKLTSDLTFAYER-LSHFRCELLRRGVQAQPLNVGFCEQ-EFE'
'||: |||:||||::|::|||:| |||:: |:|:: ::|| :||:||:||:|:|||||: |||:|:|: :| ::::::: :: ::: : : : |:::|::| :|:::: :: : : | ||:: |:|||||: :||:|:::|| :|:|:|:| | ||::| : | :::| :| :::: ::|:: : : : : : : |: |||:| : | |: : | : :: ::: ||: : : :::: | :| : || :: : :::: : : : |:|:|: :|:| :| :| |:||||:|:|||||||: :: | :| | | | |: |: |: : :| | | |'
'MALVKLNTFHWHITDSHSFPLEVKKRPELHKLGAYSQR-QVYTRRDVAEVVEYGRVRGIRVMPEFDAPAHVGEGWQHKNMTACFNAQPWKSFCVEPPCGQLDPTVNEMYDVLEDIYGTMFDQFNPDIF-HMGGDEVSTSCWNSSQPIQQWMKKQGWGLETADFMRLWGHFQTEALGRVDKVANGTHTPIILWTSGLTEEPFIDEYLNPERYIIQIWTTGVDPKVKKILERGYKIIVSNYDALYLDCGGAGWVTDGNNWCSPYIGWQKVYDNSLKSIAGDYEHHVLGAEGAIWSEQIDEHTLDNRFWPRASALAERLWSNP-AEGWRQAESRLLLH-RQRLVDNGLGAEAMQPQWCLQNEHE'
Score = 152
Plot the scores, calculate the parameters of the distribution and overlay the PDF on the bar chart.
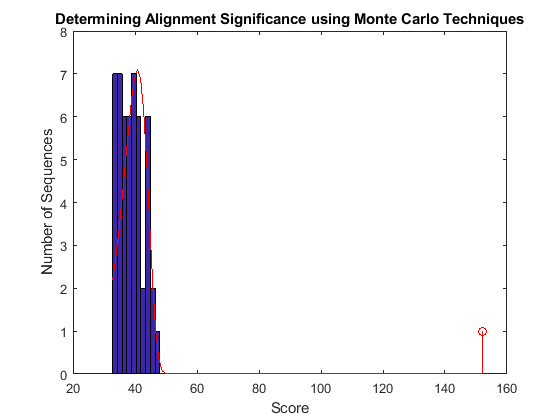
figure hist(localscores,buckets) title('Determining Alignment Significance using Monte Carlo Techniques'); xlabel('Score'); ylabel('Number of Sequences'); hold on; stem(lscore,1,'r') parmhat = evfit(localscores) x = min(localscores):max([localscores;lscore]); y = evpdf(x,parmhat(1),parmhat(2)); [v, c] = hist(localscores,buckets); binWidth = c(2) - c(1); scaleFactor = n*binWidth; plot(x,scaleFactor*y,'r'); hold off;
parmhat = 40.8331 3.9312
You might like to experiment to see if there are significant differences in the distribution of scores generated with randperm and randseq.
With the local alignment it appears that the alignment is statistically significant. In fact, looking at the local alignment shows a very good alignment for the full length of the Hexo1 sequence.
close all;
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)